Bài 1: Tổng quan về PostgreSQL High Availability
Tìm hiểu lý do cần High Availability, so sánh các giải pháp HA phổ biến (Patroni, Repmgr, Pacemaker) và nắm vững kiến trúc tổng quan của hệ thống PostgreSQL HA.

Mục tiêu bài học
Sau bài học này, bạn sẽ:
- Hiểu được tại sao High Availability (HA) quan trọng cho hệ thống database
- Nắm vững các phương pháp triển khai HA cho PostgreSQL
- So sánh được ưu nhược điểm của Patroni, Repmgr và Pacemaker
- Hiểu kiến trúc tổng quan của hệ thống PostgreSQL HA
1. Tại sao cần High Availability?
1.1. Vấn đề với Single Point of Failure (SPOF)
Trong một hệ thống database truyền thống với single server:

Hậu quả khi database server gặp sự cố:
- Downtime: Ứng dụng không thể truy cập dữ liệu
- Mất doanh thu: Mỗi phút downtime có thể tốn hàng triệu đồng
- Mất uy tín: Người dùng không thể sử dụng dịch vụ
- Mất dữ liệu: Nếu không có backup kịp thời
1.2. Các nguyên nhân gây downtime phổ biến
| Nguyên nhân | Tỷ lệ | Ảnh hưởng |
|---|---|---|
| Lỗi phần cứng (disk, RAM, CPU) | 30% | Cao |
| Lỗi mạng | 20% | Trung bình |
| Lỗi phần mềm/bug | 25% | Cao |
| Maintenance có kế hoạch | 15% | Có thể kiểm soát |
| Lỗi con người | 10% | Cao |
1.3. High Availability là gì?
High Availability (HA) là khả năng hệ thống duy trì hoạt động liên tục ngay cả khi một hoặc nhiều thành phần gặp sự cố.
Các chỉ số đo lường HA:
| Availability | Downtime/năm | Downtime/tháng | Mức độ |
|---|---|---|---|
| 99% (2 nines) | 3.65 ngày | 7.2 giờ | Thấp |
| 99.9% (3 nines) | 8.76 giờ | 43.2 phút | Trung bình |
| 99.99% (4 nines) | 52.56 phút | 4.32 phút | Cao |
| 99.999% (5 nines) | 5.26 phút | 25.9 giây | Rất cao |
1.4. Lợi ích của HA
Business Benefits:
- Giảm thiểu downtime và mất doanh thu
- Tăng độ tin cậy của hệ thống
- Cải thiện trải nghiệm người dùng
- Đáp ứng SLA (Service Level Agreement)
Technical Benefits:
- Tự động failover khi primary server gặp sự cố
- Zero-downtime maintenance
- Load balancing cho read queries
- Disaster recovery
- Data protection
2. Các phương pháp HA cho PostgreSQL
2.1. Log-Shipping (WAL Shipping)

Cách hoạt động:
- Primary server ghi WAL (Write-Ahead Log) files
- WAL files được copy sang standby server
- Standby server replay WAL để đồng bộ dữ liệu
Ưu điểm:
- Đơn giản, dễ setup
- Ít tốn tài nguyên
Nhược điểm:
- Recovery Time Objective (RTO) cao (phút → giờ)
- Không có automatic failover
- Data loss có thể xảy ra
- Standby không thể query (warm standby)
2.2. Streaming Replication
Cách hoạt động:
- Primary stream WAL records realtime đến standby
- Standby apply changes ngay lập tức
- Standby có thể serve read queries (hot standby)
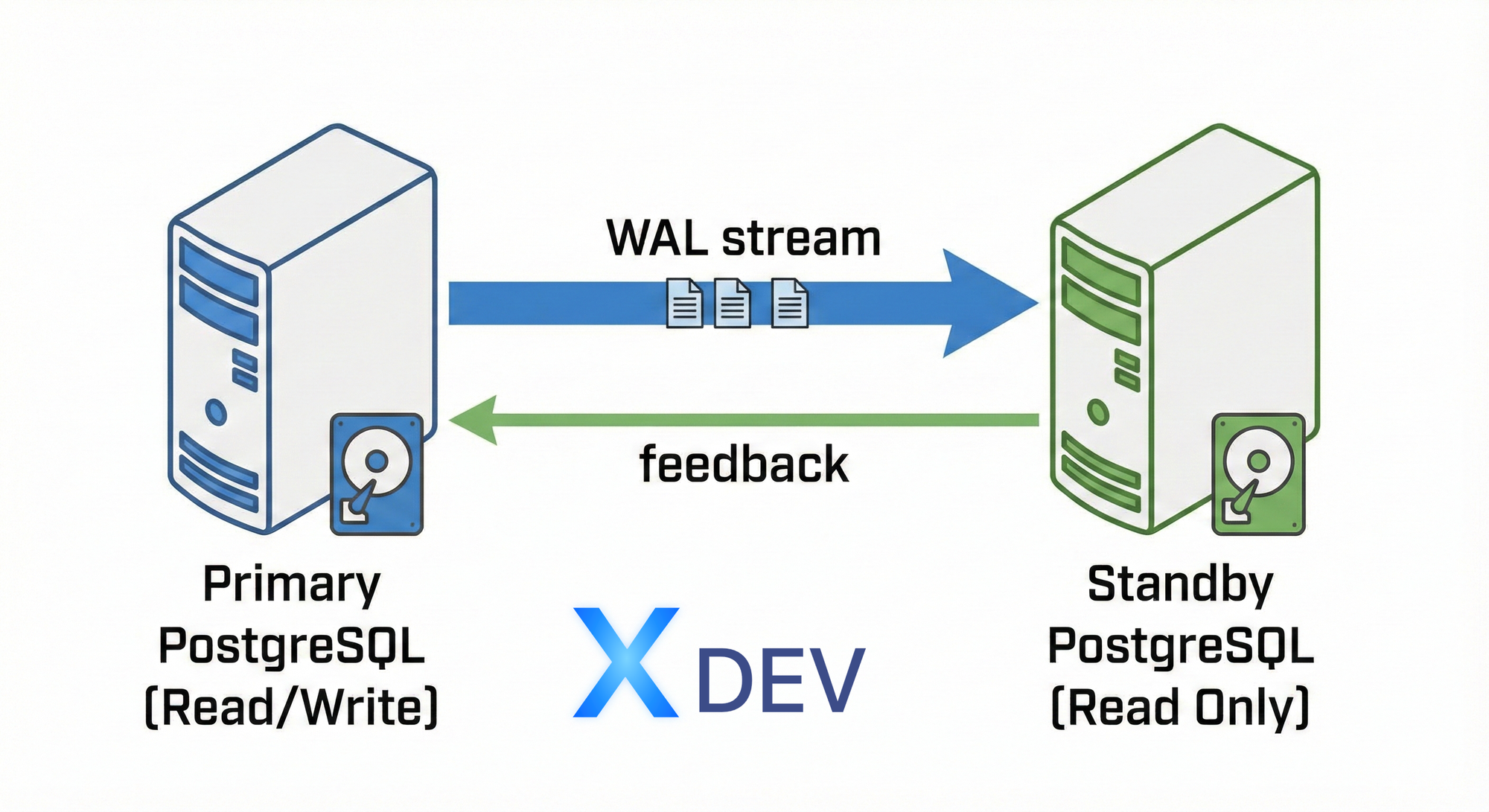
Ưu điểm:
- Latency thấp (< 1 giây)
- Hot standby có thể serve read queries
- Synchronous mode giảm data loss
Nhược điểm:
- Vẫn cần manual failover
- Cần công cụ bên ngoài để tự động hóa
2.3. Logical Replication
Cách hoạt động:
- Replicate ở mức logical (tables, rows)
- Cho phép replicate selective data
- Publisher → Subscriber model
Ưu điểm:
- Replication giữa các PostgreSQL versions khác nhau
- Selective replication (chỉ một số tables)
- Multi-master có thể (với BDR)
Nhược điểm:
- Overhead cao hơn physical replication
- Không phải giải pháp HA chính (thường dùng cho data distribution)
2.4. Shared Storage (SAN)

Ưu điểm:
- Failover nhanh (chỉ cần start PostgreSQL)
- Không có data loss
Nhược điểm:
- Đắt (cần SAN infrastructure)
- SAN trở thành single point of failure
- Phức tạp để maintain
3. So sánh: Patroni vs Repmgr vs Pacemaker
3.1. Patroni
Đặc điểm:
- Python-based
- Sử dụng DCS (etcd, Consul, ZooKeeper) để lưu cluster state
- REST API cho management
- Automatic failover thông minh
- Template-based configuration
Ưu điểm:
- ✅ Dễ cài đặt và cấu hình
- ✅ REST API mạnh mẽ
- ✅ Tích hợp tốt với Kubernetes
- ✅ Active development, community lớn
- ✅ Automatic leader election
- ✅ Rolling restart, zero-downtime updates
Nhược điểm:
- ❌ Phụ thuộc vào DCS (thêm component)
- ❌ Cần học DCS (etcd/Consul)
Use cases phù hợp:
- Cloud-native applications
- Kubernetes deployments
- Microservices architecture
- Cần automation cao
3.2. Repmgr
Đặc điểm:
- Open-source tool từ 2ndQuadrant (EnterpriseDB)
- Standalone tool, không cần DCS
- Witness node cho quorum voting
- Command-line based management
Ưu điểm:
- ✅ Không cần DCS bên ngoài
- ✅ Đơn giản hơn Patroni
- ✅ Documentation tốt
- ✅ Mature và stable
Nhược điểm:
- ❌ Ít tính năng automation hơn Patroni
- ❌ Không có REST API
- ❌ Community nhỏ hơn
- ❌ Failover phức tạp hơn
Use cases phù hợp:
- Traditional infrastructure
- Đơn giản, ít nodes
- Không muốn thêm DCS
3.3. Pacemaker + Corosync
Đặc điểm:
- High Availability cluster framework (Linux-HA)
- Quản lý nhiều loại resources, không chỉ PostgreSQL
- Voting quorum mechanism
- Fencing/STONITH để tránh split-brain
Ưu điểm:
- ✅ Mature, production-proven (20+ years)
- ✅ Quản lý nhiều services (PostgreSQL, web server, etc.)
- ✅ Fencing mechanism mạnh mẽ
- ✅ Hỗ trợ shared storage
Nhược điểm:
- ❌ Rất phức tạp để setup và maintain
- ❌ Learning curve cao
- ❌ Configuration dạng XML khó đọc
- ❌ Debugging khó khăn
Use cases phù hợp:
- Enterprise environment
- Cần quản lý nhiều services
- Có shared storage (SAN)
- Team có kinh nghiệm với Pacemaker
3.4. Bảng so sánh tổng quan
| Tiêu chí | Patroni | Repmgr | Pacemaker |
|---|---|---|---|
| Độ phức tạp | Trung bình | Thấp | Cao |
| Learning curve | Trung bình | Thấp | Rất cao |
| Setup time | Nhanh | Nhanh | Chậm |
| Automatic failover | ✅ Xuất sắc | ✅ Tốt | ✅ Xuất sắc |
| REST API | ✅ Có | ❌ Không | ❌ Không |
| Kubernetes support | ✅ Xuất sắc | ⚠️ Limited | ❌ Không |
| Community | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Documentation | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| Dependencies | DCS (etcd/Consul) | None | None |
| Best for | Modern/Cloud | Simple setups | Enterprise/Complex |
3.5. Khuyến nghị
Chọn Patroni nếu:
- Triển khai trên cloud hoặc Kubernetes
- Cần automation và REST API
- Team có kinh nghiệm với modern DevOps tools
- ✅ Đây là lựa chọn phổ biến nhất hiện nay
Chọn Repmgr nếu:
- Setup đơn giản, ít nodes (2-3)
- Không muốn phụ thuộc vào DCS
- Team quen với PostgreSQL traditional tools
Chọn Pacemaker nếu:
- Môi trường enterprise phức tạp
- Đã có sẵn Pacemaker infrastructure
- Cần quản lý nhiều services cùng lúc
- Có shared storage (SAN)
4. Kiến trúc tổng quan hệ thống Patroni + etcd
4.1. Kiến trúc 3-node cluster
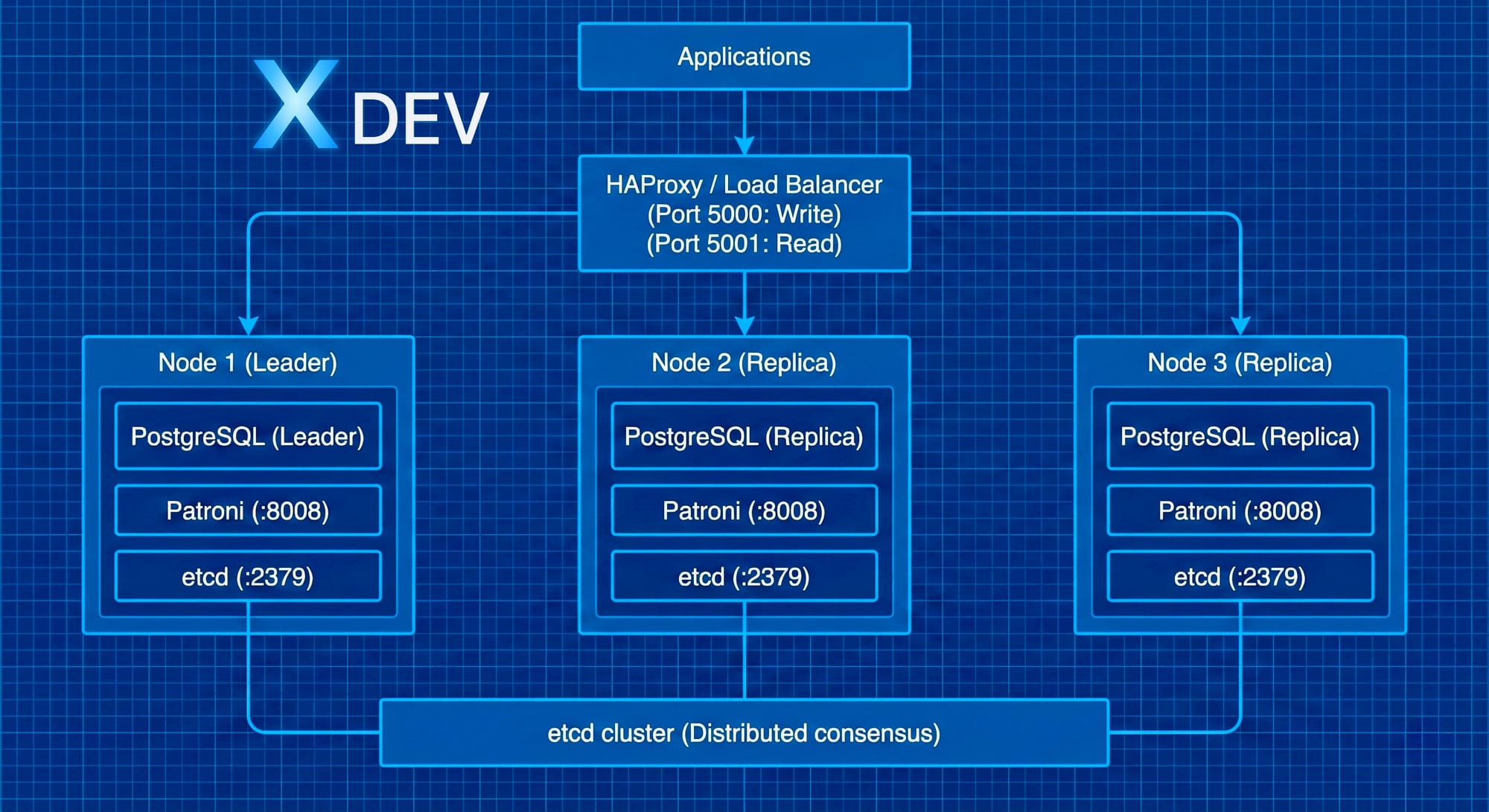
4.2. Các thành phần chính
PostgreSQL
- Database engine chính
- Một node là Leader (read/write)
- Các node khác là Replica (read-only)
- Sử dụng Streaming Replication để đồng bộ
Patroni
- Quản lý lifecycle của PostgreSQL
- Monitor health của nodes
- Thực hiện automatic failover
- Expose REST API (:8008) để query cluster state
- Đọc/ghi configuration vào DCS
etcd (DCS - Distributed Configuration Store)
- Lưu trữ cluster state và configuration
- Leader election (quyết định node nào là Leader)
- Distributed lock mechanism
- 3 nodes etcd tạo thành quorum (majority voting)
HAProxy (optional nhưng khuyến nghị)
- Load balancer
- Route write traffic → Leader
- Route read traffic → Replicas (round-robin)
- Health check và tự động route khi failover
4.3. Luồng hoạt động
1. Normal Operations (Trạng thái bình thường)
1. Application gửi query → HAProxy
2. HAProxy kiểm tra health check
3. Route write → Leader, read → Replicas
4. Patroni trên mỗi node:
- Gửi heartbeat vào etcd mỗi 10s
- Update health status
- Maintain leader lease
2. Leader Failure Detection
1. Node 1 (Leader) gặp sự cố → stop heartbeat
2. etcd phát hiện: leader lease expired (30s)
3. Patroni trên Node 2 và Node 3 nhận ra
4. Leader election được trigger
3. Automatic Failover Process
Timeline: 0s ──────────► 30s ──────► 45s ──────► 60s
│ │ │ │
Leader dies etcd detects New leader Applications
lease expire elected reconnect
(Node 2)
Node 1: LEADER ──────► DOWN ──────────────────► STANDBY (sau khi recover)
Node 2: REPLICA ─────────────────► LEADER ────► LEADER
Node 3: REPLICA ──────────────────────────────► REPLICA
4. Sau Failover
- Node 2 trở thành Leader mới
- Node 3 vẫn là Replica, đổi replication source sang Node 2
- HAProxy tự động detect và route traffic sang Node 2
- Node 1 (khi recover) sẽ join lại như Replica
4.4. Các scenario quan trọng
Scenario 1: Planned Switchover
# Admin muốn maintenance Node 1 (Leader)
$ patronictl switchover postgres-cluster
# Patroni sẽ:
1. Tạm dừng ghi vào Leader hiện tại
2. Đợi Replica sync hoàn toàn (zero lag)
3. Promote Replica → Leader
4. Demote Leader cũ → Replica
5. Zero data loss, downtime < 5s
Scenario 2: Split-brain Prevention
Tình huống: Network partition giữa nodes
etcd quorum (3 nodes):
- Partition A: Node 1, Node 2 (2 nodes = majority)
- Partition B: Node 3 (1 node = minority)
Kết quả:
✅ Partition A: Tiếp tục hoạt động, có thể elect leader
❌ Partition B: Không thể elect leader (không đủ quorum)
→ Tránh được 2 leaders cùng tồn tại!
Scenario 3: Node Recovery
Node 1 recover sau khi die:
1. Patroni start và đọc cluster state từ etcd
2. Nhận ra Node 2 đang là Leader
3. Tự động rejoin như Replica
4. Sử dụng pg_rewind để sync data nếu có divergence
5. Bắt đầu streaming replication từ Node 2
4.5. Cấu hình timeline (thông số quan trọng)
# patroni.yml
bootstrap:
dcs:
ttl: 30 # Leader lease time (30s)
loop_wait: 10 # Check interval (10s)
retry_timeout: 10 # Retry time
maximum_lag_on_failover: 1048576 # Max lag for failover candidate (1MB)
Giải thích:
ttl: 30: Leader phải renew lease mỗi 30s, nếu không sẽ bị coi là deadloop_wait: 10: Patroni check health mỗi 10s- Failover trigger: khi (ttl - loop_wait) hết → ~20-30s
5. Tổng kết
Key Takeaways
- High Availability là bắt buộc cho production systems để giảm downtime và mất dữ liệu
- Streaming Replication + Automatic Failover là phương pháp HA phổ biến nhất cho PostgreSQL
- Patroni là lựa chọn tốt nhất cho hầu hết use cases hiện đại:
- Dễ setup và maintain
- Automatic failover thông minh
- REST API mạnh mẽ
- Tích hợp tốt với cloud/K8s
- Kiến trúc 3-node với Patroni + etcd cung cấp:
- Automatic failover (RTO < 30s)
- Zero data loss với sync replication
- Split-brain prevention
- Scalability cho read workloads
Bài tập về nhà
- Tính toán downtime cho hệ thống của bạn với các mức availability khác nhau (99%, 99.9%, 99.99%)
- Vẽ kiến trúc HA cho use case cụ thể của bạn (số nodes, data centers, RTO/RPO requirements)
- So sánh chi phí giữa việc sử dụng HA và chấp nhận downtime cho business của bạn
Chuẩn bị cho bài tiếp theo
Bài 2 sẽ đi sâu vào Streaming Replication - nền tảng của PostgreSQL HA:
- Cơ chế hoạt động chi tiết của WAL
- Synchronous vs Asynchronous replication
- Replication slots
- Lab: Setup replication thủ công